
MCP Server深度解析:AI应用的标准化协议
引言:AI应用集成的困境与突破在 AI 快速发展的今天,我们看到越来越多的 AI 应用涌现:从 Claude、ChatGPT 到各类垂直领域的 AI 助手。然而,每个 AI 应用都有自己的数据接入方式、API 标准和集成方法,这就像互联网早期各家公司都有自己的协议标准一样,导致开发者需要为每个 AI 应用单独适配。 Anthropic 公司在 2024 年推出的 MCP (Model Context Protocol,模型上下文协议) 正是为了解决这一痛点而生。它提供了一套标准化的协议,让 AI 应用能够以统一的方式访问各类数据源和工具,就像 HTTP 协议统一了 Web 通信一样。 一、什么是 MCP Server?1.1 MCP Server 是什么:给 AI 的「能力网关」MCP Server 是基于 Model Context Protocol 协议实现的服务端程序,它充当 AI 应用与外部资源之间的桥梁。 graph LR A[AI应用<br/>Claude/ChatGPT] --> B[MCP Client]...
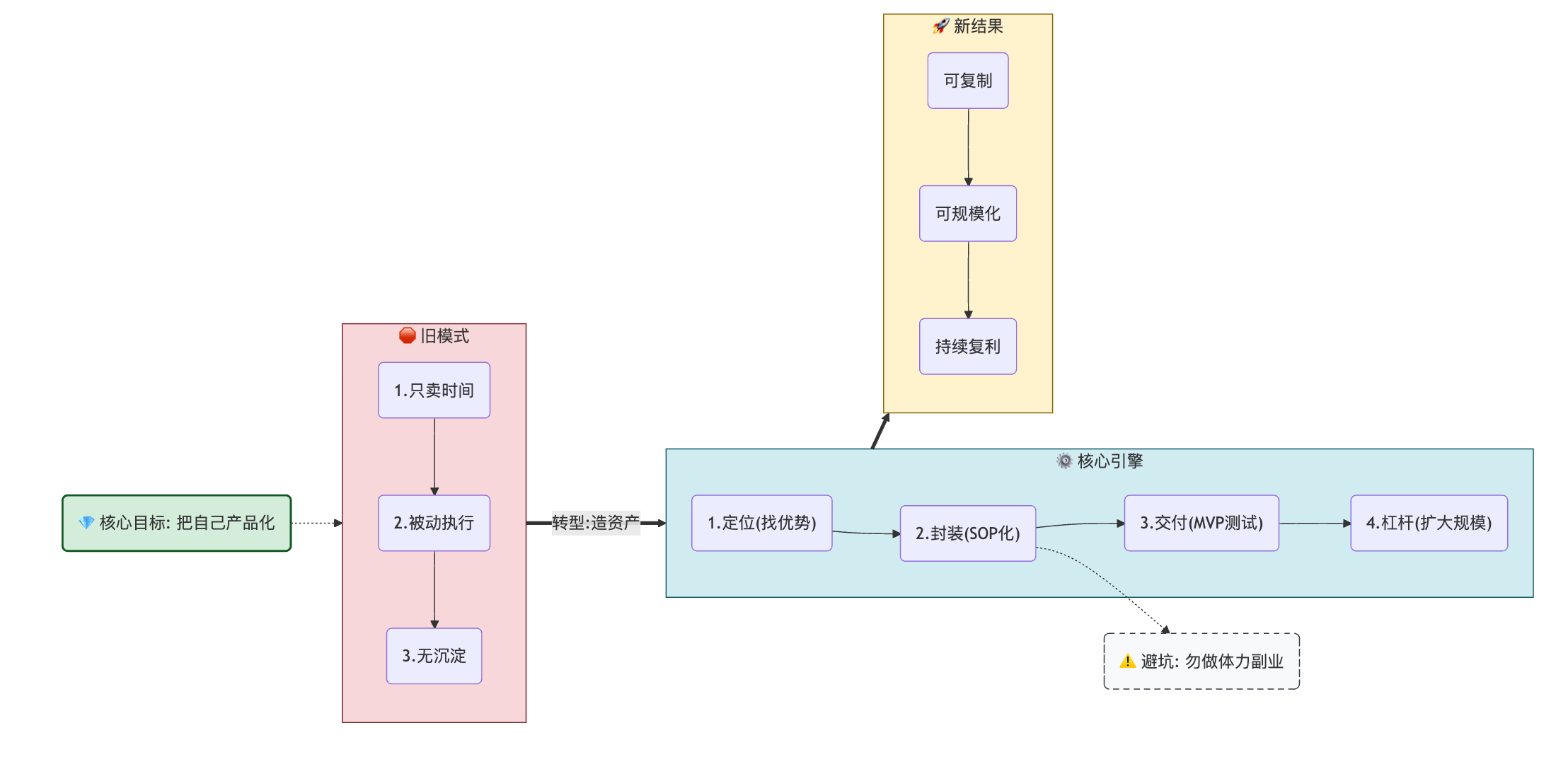
从年底人才盘点评委席,看打工人为什么要把自己"产品化"
一个人的一生,最重要的事业就是经营好自己。把“自己”当作一款持续迭代的产品,建立清晰的定位、稳定的价值交付、可规模化的增长与运营体系,你会更快、更稳地抵达想去的地方。 作为公司年底人才盘点的评委,这几年我反复看到同一个画面:有的人在原地踏步,有的人忙得昏天黑地却难有突破,还有的人明明聪明、肯干,却在关键节点一再与机会擦肩而过。更扎心的是,他们中的绝大多数,并不是“不够努力”,而是不知道该往哪里用力。 如果你把自己看成一个“岗位上的螺丝钉”,你自然会习惯性地等任务、做执行、盯考核;但如果你开始把自己当成一款“产品”,你就会倒过来思考: 我到底解决什么问题? 我相对于同龄人、同岗位的独特价值是什么? 这些价值,能不能被封装成资产,在我不亲自盯着的时候也能持续发挥作用? 这正是《纳瓦尔宝典》里“把自己产品化”的底层逻辑,而在我一次次的人才评审中,也越来越确定:能把自己产品化的人,几乎都不会被时代轻易淘汰。 一、从评委席看到的打工人困境人才盘点的时候,评委不会只看“你有多辛苦”,而是看“你这两三年到底长成了一个什么样的‘产品’”。在这个视角下,很多职场困境被放大得格外清晰。...
一次线上Redis集群节点主从切换引起的应用重启问题排查处理
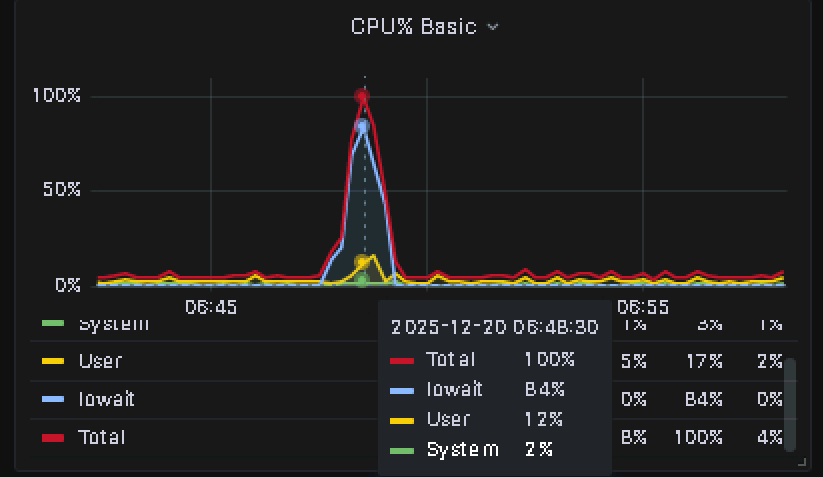
一、问题背景某日生产环境出现大规模应用重启告警,经过初步排查发现与Redis集群节点主从切换有关。该问题导致多个核心服务不可用,对业务产生了较大影响。 问题环境: Redis集群架构 Kubernetes容器化部署 Spring Boot微服务架构 二、问题现象问题发生时,监控系统显示大量应用实例出现重启现象,具体表现为: 应用层面: 多个微服务实例频繁重启 日志异常: 应用日志中出现大量Redis连接异常 监控指标: Redis集群监控显示某个节点发生主从切换 业务影响: 部分核心接口响应超时,用户体验下降 图1:Redis集群节点资源监控图示 三、排查过程3.1 初步分析通过监控系统初步定位,发现问题与Redis集群节点主从切换存在强关联性: 时间关联性:应用重启时间与Redis节点主从切换时间高度吻合 影响范围:所有依赖该Redis集群的服务均受到影响 初步判断:可能是Redis集群拓扑变化导致应用无法正常连接 3.2 深入排查为进一步定位问题根因,我们进行了深入的技术排查: 排查工具与方法: 查看应用日志,分析异常堆栈信息 检查Redis集群状态和节点信息...

一次生产流量攻击防御与解决方案
一、问题背景1.1 问题发现某天上班后,运维反馈监控系统突然告警,网站带宽使用率持续飙升至80%以上,服务器CPU负载异常。通过查看Nginx访问日志发现,某个静态资源文件遭受了大规模的异常访问。 1.2 日志分析正常访问日志示例首先查看正常时段的访问日志,流量分布较为均匀: {"@timestamp":"2025-11-11T09:00:00+08:00","host":"172.25.192.5","client":"183.44.115.70","size":792,"responsetime":0.001,"url":"/uploadfiles/nav/nav3_img3.png","status":"200"} {"@timestamp":"2025-11-11T09:00:00+08:00","host":"172.25.192.5","client":"119.134.146.224","size":1222,"responsetime":0.002,"url":"/uploadfiles/2024/05/20240506180621...

站在31岁的人生十字路口,我选择放下焦虑,与自己和解
三十而立,是一个被赋予了太多期望的词。我们曾以为,到了这个年纪就该事业有成、家庭美满,活成一个”标准答案”。然而,当31岁的里程碑悄然来临,我们才发现,人生没有标准答案,只有不断叩问自己、与自己和解的过程。 一、焦虑,是成长的必经之路最近,我常常感到一种莫名的焦虑。它不像年轻时的迷茫,那种对未来的不确定性。现在的焦虑更像是站在一个山顶,回头望去,有起有落,有清晰的足迹,但前方却又是一片迷雾。 我开始意识到,31岁不再是那个可以肆意挥霍时间的少年。我们开始算计沉没成本,每一次选择都背负着更高的风险。肩上的责任越来越重,它不只是工作的 KPI,更是对家人、对未来的承诺。 曾国藩说:”物来顺应,未来不迎,当时不杂,既过不恋。“ 这句话曾被我奉为圭臬。但真正的感悟,是在这31年的人生轨迹里,我才明白它不是让我们被动接受,而是告诉我们,面对焦虑,与其被动逃避,不如主动剖析,搞清楚焦虑的根源,才能真正与之和解。 二、撕开自我的”理想画像”,看见真实的自己为了看清前路,我决定做一次深度自我解剖,将自己的人生分成两个阶段:毕业前和工作后。这不是简单的履历罗列,而是去洞察那些塑造了...

JMX-Exporter虚拟机JVM监控采集部署
一、背景简介虚拟机部署的Java应用没有集成SpringBoot自带监控Actuator,需要额外手动配置采集JVM监控。JMX-Exporter作为Prometheus生态系统中重要的组件,能够将JMX(Java Management Extensions)指标转换为Prometheus格式,实现对Java应用的深度监控。 核心解决问题: 传统Java应用缺乏现代化监控指标暴露 需要统一监控数据格式对接Prometheus 实现JVM性能指标的实时采集和分析 二、JMX Agent部署步骤2.1. 部署文件在开始部署之前,需要准备以下核心文件: 文件类型 文件名称 说明 JVM监控Agent jmx_prometheus_javaagent-1.2.0.jar JMX指标收集器 监控配置文件 exporter.yaml JMX指标采集规则配置 exporter.yamlrules: - pattern: ".*" 版本说明: 建议使用JMX Prometheus JavaAgent 1.2.0或更新版本 配置文件需要根...

MySQL主从监控配置-Helm部署方案
一、背景简介生产环境的MySQL监控面临着部署复杂、标签不统一、管理困难等问题。传统方式中每个MySQL实例都需要单独部署一个exporter,部署方式繁琐,采集的指标标签不统一,无法在监控图表上快速检索查看。 核心解决问题: 简化MySQL监控的部署流程 统一监控指标标签格式 支持灵活的多实例监控管理 提供安全的认证信息存储 本方案采用Helm部署mysql-exporter实现MySQL监控采集,可以灵活增加mysql监控实例,大大简化了运维管理复杂度。 二、部署文件准备2.1. 必需文件清单 文件类型 文件名称 说明 Helm Charts prometheus-mysql-exporter-2.10.0.tgz prometheus-mysql-exporter chart部署包 配置文件 mysql-exporter-values.yaml mysql-exporter配置文件 版本说明: 推荐使用prometheus-mysql-exporter 2.10.0或更新版本 Chart包包含了完整的Kubernetes资源定义 values...

Redis集群监控配置-Helm部署方案
一、背景简介生产环境的Redis监控告警一直存在准确性问题,通过深入排查发现redis-exporter采集方式不正确,导致监控指标偏差和告警误报。为了解决这些问题,采用标准化的Helm部署方式来实现Redis集群监控采集。 核心解决问题: 修复Redis监控指标采集不准确的问题 统一Redis集群监控部署方式 提供安全的认证信息管理 支持多集群的灵活配置管理 本方案通过Helm部署redis-exporter实现Redis集群监控采集,确保监控数据的准确性和可靠性。 二、部署文件准备2.1. 必需文件清单 文件类型 文件名称 说明 Helm Charts prometheus-redis-exporter-6.9.0.tgz prometheus-redis-exporter chart部署包 配置文件 redis-exporter-values.yaml redis-exporter配置文件 版本说明: 推荐使用prometheus-redis-exporter 6.9.0或更新版本 Chart包包含了完整的Kubernetes资源定义 va...
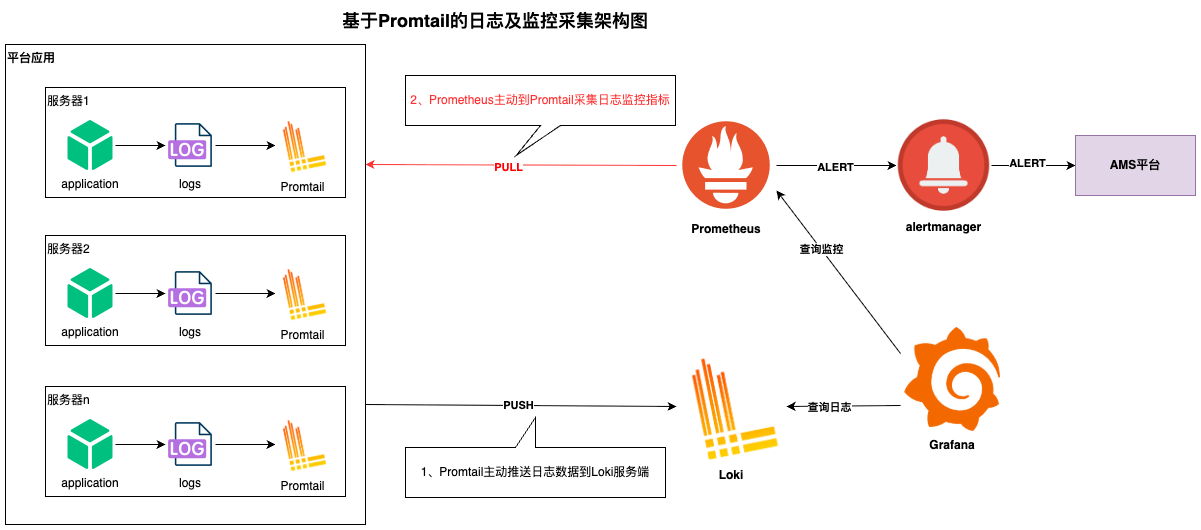
生产应用日志监控告警方案
一、背景简介生产之前出现过许多业务异常的情况未能及时发现,这些异常出现时有大量的异常日志打印,但是由于缺乏日志监控,未能及时发现异常并进行处理。 该方案计划对生产所有的异常日志进行监控及告警配置,及时发现生产日志异常,快速响应处理。 二、日志及监控采集方案生产的日志采集和监控均基于Promtail组件实现,具体的原理如下: Promtail监听日志文件变化,主动将日志数据推送到Loki服务端实现日志数据采集; Promtail采集日志内容时根据配置做日志监控指标聚合运算,Prometheus主动到Promtail拉取聚合的日志监控指标; 图:基于Promtail的日志和日志监控采集架构 2.1. 日志监控两种实现方式对比日志监控两种实现方式包括:Promtail 中的 metrics 阶段和 Loki 的 ruler 组件。 方案一:Promtail在日志采集时进行日志监控指标的收集 监控指标采集速度高、无延迟 告警规则使用Prometheus的告警规则即可 需要在Promtail侧配置日志告警指标 方案二:Loki的Ruler组件定时根据配置查询 根据配置...
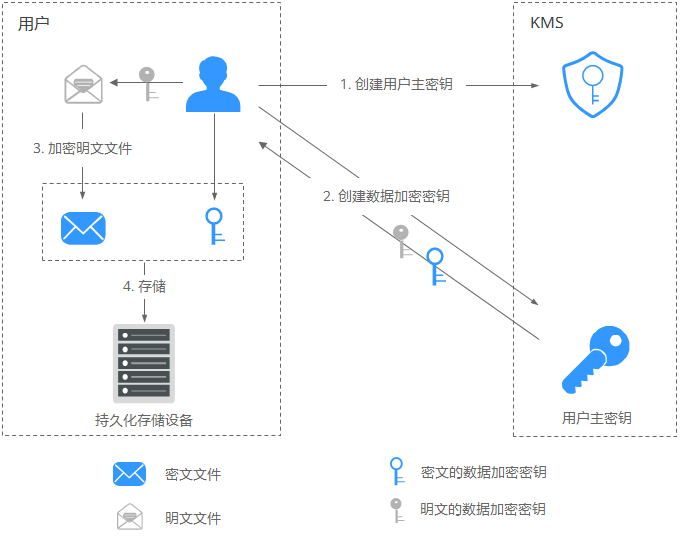
海量业务数据加解密方案的落地与实践
一、背景简介根据数据安全规范与标准及企业合法合规运营,业务系统需要对海量的业务数据进行加密,保护数据的安全。 1.1 业务数据的安全性要求 敏感业务数据需要加密存储 数据查询需要进行解密 加密数据的密钥支持定期轮换 二、方案预研对于上述业务数据的加密要求,一般采用加密性能较高的对称加密算法,如:AES、国密SM4等。系统的数据加解密及密钥的管理及定期轮换,行业内一般是采用密钥管理服务(Key Management Service,简称KMS)来解决,下面我们就预研一下KMS的使用。 2.1 密钥管理服务KMS密钥管理,即密钥管理服务(Key Management Service,KMS),是一种安全、可靠、简单易用的密钥托管服务,帮助您轻松创建和管理密钥,保护密钥的安全。 KMS通过使用硬件安全模块HSM(Hardware Security Module)保护密钥的安全,所有的用户密钥都由HSM中的根密钥保护,避免密钥泄露。 KMS对密钥的所有操作都会进行访问控制及日志跟踪,提供所有密钥的使用记录,满足审计和合规性要求。 2.2 KMS服务选型密钥管理服务使用硬件安全模块HSM...