分库分表设计方案
一、背景介绍
系统数据库主要分为两个数据库,一个是主要的业务数据存储库,在该库下进行了分表操作;另一个是业务关联性较小的数据库,未进行分表。在当前业务场景下,系统每天的消息发送量基本分布在100万 ~ 3000万之间。消息下发后,用户可以查看消息发送记录,及用户接受状态。系统采用了按天分表的策略,提前为存储消息记录的表按天创建分表,每个大表将会按天创建366个分表,分表以月日为后缀。
1.1 按天分表的优点
- 用户可以以发送日期为时间限度,查询、导出当天的发送记录及用户接受状态。
- 可以通过日期条件,限定事务范围,简化分表事务问题。
- 分表规则简单,方便基于数据库各类连表查询操作。
1.2 分库分表遇到的问题
- 在开发新业务的过程中,分表数量急速增长,目前系统的分表数量已达7000多。
- 分表数据分布不均匀,有些表的数据库只有几十万或更少,而有的表的量超过了千万。
- 分表数量超过千万级,客户查询时会影响数据库性能,当前的分表机制无法做动态扩容。
二、分库分表方案
分库分表的采用的常见方案垂直拆分和水平拆分。
2.1 垂直拆分
垂直分表
垂直分表主要主要针对数据列较多的宽表,一般是表中的字段较多,将不常用的, 数据较大,长度较长(比如text类型字段)的列拆分到“扩展表“。 一般是针对那种几百列的大表,也避免查询时,数据量太大造成的“跨页”问题。
垂直分库
垂直分库主要是对系统中业务进行拆分,切分后不同的业务数据存放到不同的数据库。可以将这些数据库部署到不同的机器上,避免单机CPU、内存、IO瓶颈问题。此外还可以独立对高并发的业务进行性能单独优化而不影响其它业务。
2.2 水平拆分
水平分表
针对数据量巨大打单表(比如订单表)按照某种规则(如时间,哈希取模等),将数据路由到不同的分表中。但是这些分表仍处于一个数据库中,单库具有IO瓶颈问题。
水平分库分表
单独的水平分表会遇到单机数据库性能瓶颈及压力,如IO、连接数等硬件资源的限制。可以将单表数据按分表规则先路由到不同的数据库,然后再路由数据库内的不同分表之中。水平分库分表能够有效的缓解单机和单库的性能瓶颈和压力,突破IO、连接数、硬件资源等的瓶颈。
2.3 水平分库分表切分规则
RANGE
从0到1000万一个表,1000万到2000万一个表;
HASH取模
- 按用户ID哈希取模(避免分库事务,但数据可能会分布不均匀)
- 按订单ID哈希取模(数据分布较均匀,会有分库事务问题)
区域
比如按照华东,华南,华北这样来区分业务,七牛云应该就是如此。时间
按照时间切分,就是将6个月前,甚至一年前的数据切出去放到另外的一张表,因为随着时间流逝,这些表的数据 被查询的概率变小,所以没必要和“热数据”放在一起,这个也是“冷热数据分离”。
三、分库分表面临的问题
事务支持
分库分表后,就成了分布式事务了。如果依赖数据库本身的分布式事务管理功能去执行事务,将付出高昂的性能代价; 如果由应用程序去协助控制,形成程序逻辑上的事务,又会造成编程方面的负担。多库结果集合并
跨库join连接查询
分库分表后表之间的关联操作将受到限制,我们无法join位于不同分库的表,也无法join分表粒度不同的表, 结果原本一次查询能够完成的业务,可能需要多次查询才能完成。 粗略的解决方法: 全局表:基础数据,所有库都拷贝一份。 字段冗余:这样有些字段就不用join去查询了。 系统层组装:分别查询出所有,然后组装起来,较复杂。
四、分库分表产品
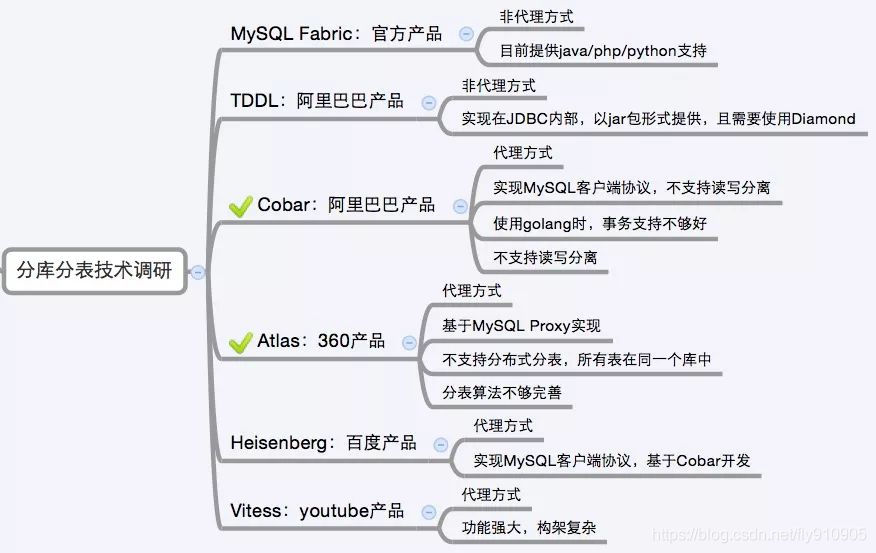
参考文章:分库分表:中间件方案对比
总结
分库分表常用的方法就是垂直拆分和水平拆分,我们在进行分库分表设计时需要结合业务场景及资源环境去充分考虑。