Java中一个对象占用多少个字节
说明:本文内容参考文章:码辣架构-Java对象的内存布局,详解内容请阅读原文。
一、问题背景
在开发过程中,我们经常使用JVM进行缓存一些数据来提高程序的性能,但是我们需要对缓存的数据进行大小估算,防止产生OOM问题,为保证估算的准确性,需要了解一个Java对象在内存中具体占用多少个字节。
二、一个Java对象的组成
| 组成部分 | 对象头(object header) | 实例数据(Instance Data) | 对齐填充(Padding) |
|---|---|---|---|
| 说明 | 包括了关于堆对象的布局、类型、GC状态、同步状态和标识哈希码的基本信息。Java对象和vm内部对象都有一个共同的对象头格式。 | 主要是存放类的数据信息,父类的信息,对象字段属性信息。 | 为了字节对齐,填充的数据,不是必须的。 |
| 大小 | 12 byte | 基本类型数据类型和引用类型的大小 | 对象大小不满足8byte的倍数时进行填充 |
提示:JDK6之后默认都是开始指针压缩的,所以对象头中
mark word占用8个byte,klass pointer占用4个byte
object header
Common structure at the beginning of every GC-managed heap object. (Every oop points to an object header.) Includes fundamental information about the heap object’s layout, type, GC state, synchronization state, and identity hash code.
Consists of two words. In arrays it is immediately followed by a length field. Note that both Java objects and VM-internal objects have a common object header format.
mark word
The first word of every object header. Usually a set of bitfields including synchronization state and identity hash code. May also be a pointer (with characteristic low bit encoding) to synchronization related information. During GC, may contain GC state bits.
用于存储对象自身的运行时数据,如哈希码(HashCode)、GC分代年龄、锁状态标志、线程持有的锁、偏向线程ID、偏向时间戳等等。
Mark Word在32位JVM中的长度是32bit,在64位JVM中长度是64bit。
打开openjdk的源码包,对应路径/openjdk/hotspot/src/share/vm/oops,Mark Word对应到C++的代码markOop.hpp,可以从注释中看到它们的组成,本文所有代码是基于Jdk1.8。
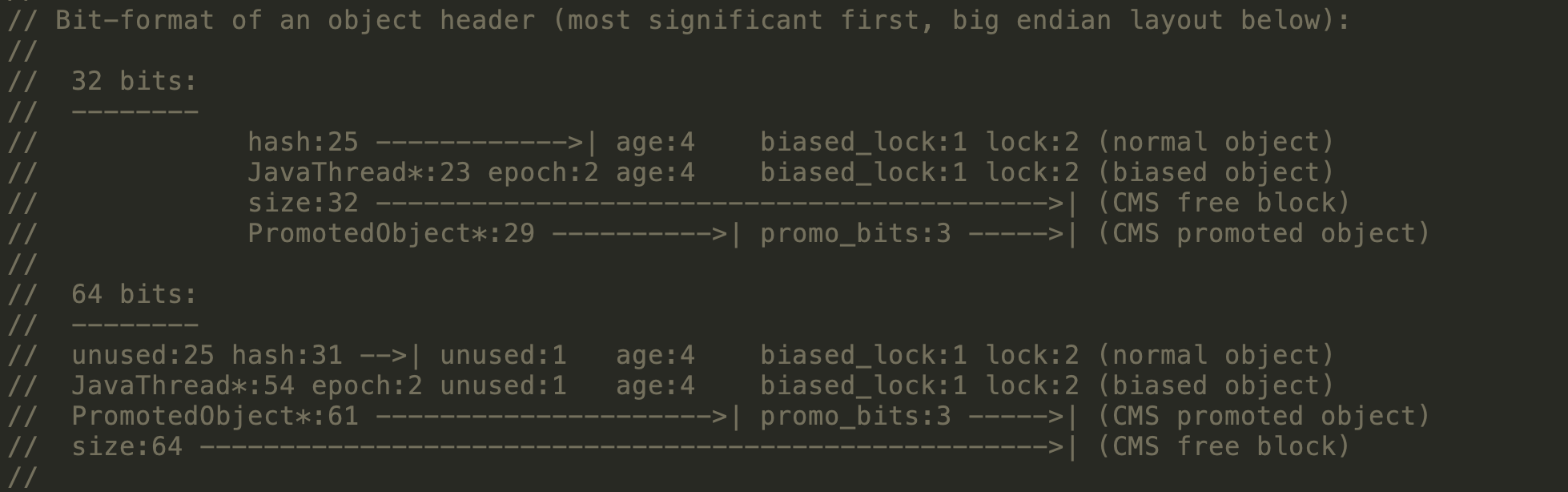
Mark Word在不同的锁状态下存储的内容不同,在32位JVM中是这么存的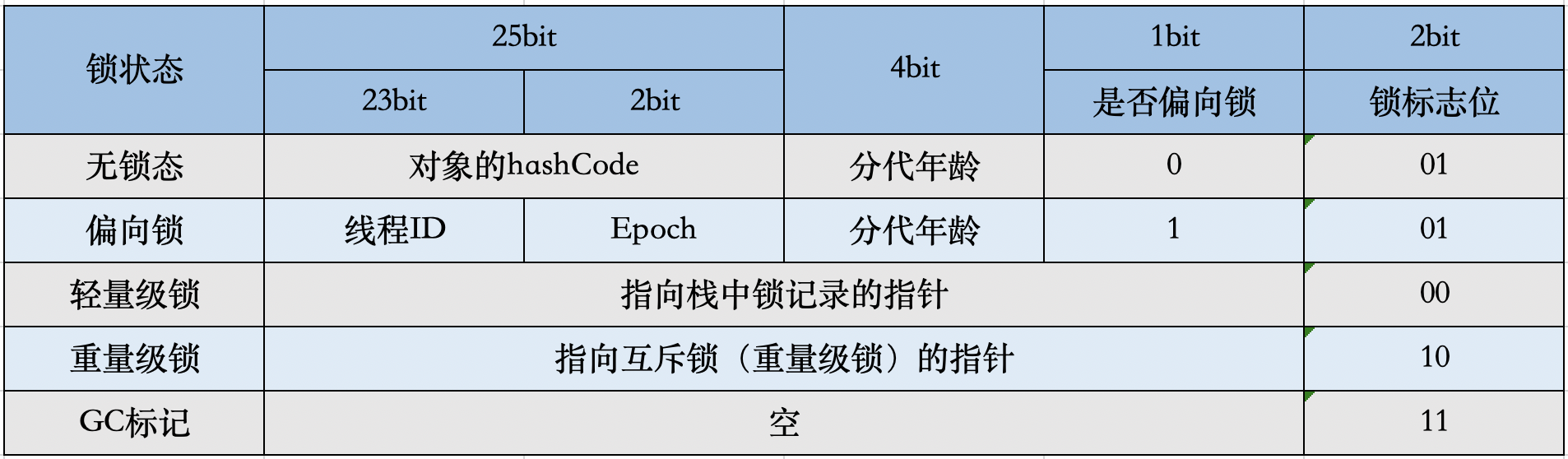
在64位JVM中是这么存的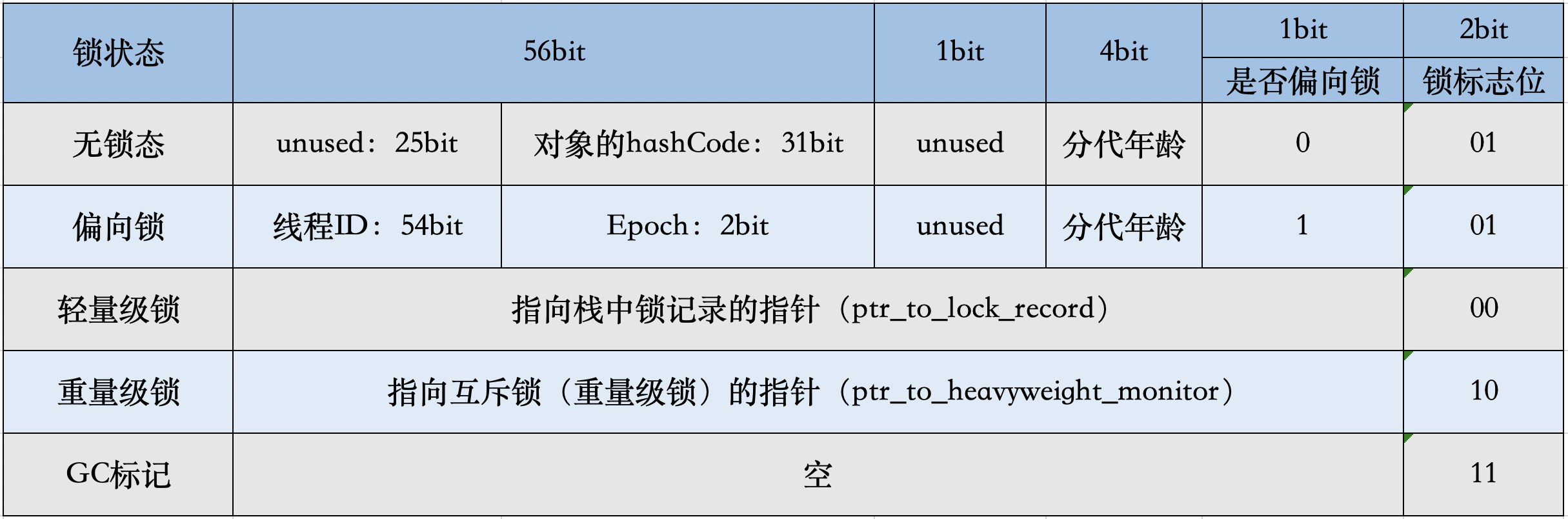
虽然它们在不同位数的JVM中长度不一样,但是基本组成内容是一致的。
- 锁标志位(lock):区分锁状态,11时表示对象待GC回收状态, 只有最后2位锁标识(11)有效。
- biased_lock:是否偏向锁,由于无锁和偏向锁的锁标识都是 01,没办法区分,这里引入一位的偏向锁标识位。
- 分代年龄(age):表示对象被GC的次数,当该次数到达阈值的时候,对象就会转移到老年代。
- 对象的hashcode(hash):运行期间调用System.identityHashCode()来计算,延迟计算,并把结果赋值到这里。当对象加锁后,计算的结果31位不够表示,在偏向锁,轻量锁,重量锁,hashcode会被转移到Monitor中。
- 偏向锁的线程ID(JavaThread):偏向模式的时候,当某个线程持有对象的时候,对象这里就会被置为该线程的ID。 在后面的操作中,就无需再进行尝试获取锁的动作。
- epoch:偏向锁在CAS锁操作过程中,偏向性标识,表示对象更偏向哪个锁。
- ptr_to_lock_record:轻量级锁状态下,指向栈中锁记录的指针。当锁获取是无竞争的时,JVM使用原子操作而不是OS互斥。这种技术称为轻量级锁定。在轻量级锁定的情况下,JVM通过CAS操作在对象的标题字中设置指向锁记录的指针。
- ptr_to_heavyweight_monitor:重量级锁状态下,指向对象监视器Monitor的指针。如果两个不同的线程同时在同一个对象上竞争,则必须将轻量级锁定升级到Monitor以管理等待的线程。在重量级锁定的情况下,JVM在对象的ptr_to_heavyweight_monitor设置指向Monitor的指针。
klass pointer
The second word of every object header. Points to another object (a metaobject) which describes the layout and behavior of the original object. For Java objects, the “klass” contains a C++ style “vtable”.
即类型指针,是对象指向它的类元数据的指针,虚拟机通过这个指针来确定这个对象是哪个类的实例。
JVM默认开启了指针压缩 ,对象头占了12byte,类型指针占4个byte,如果关闭指针压缩则类型指针占8个byte。
jdk8版本是默认开启指针压缩的,可以通过配置vm参数开启关闭指针压缩,-XX:-UseCompressedOops。
实例数据
如果对象有属性字段,则这里会有数据信息。如果对象无属性字段,则这里就不会有数据。根据字段类型的不同占不同的字节,例如boolean类型占1个字节,int类型占4个字节等等;
对齐数据
对象可以有对齐数据也可以没有。默认情况下,Java虚拟机堆中对象的起始地址需要对齐至8的倍数。如果一个对象用不到8N个字节则需要对其填充,以此来补齐对象头和实例数据占用内存之后剩余的空间大小。如果对象头和实例数据已经占满了JVM所分配的内存空间,那么就不用再进行对齐填充了。
所有的对象分配的字节总SIZE需要是8的倍数,如果前面的对象头和实例数据占用的总SIZE不满足要求,则通过对齐数据来填满。
为什么要对齐数据?
字段内存对齐的其中一个原因,是让字段只出现在同一CPU的缓存行中。如果字段不是对齐的,那么就有可能出现跨缓存行的字段。也就是说,该字段的读取可能需要替换两个缓存行,而该字段的存储也会同时污染两个缓存行。这两种情况对程序的执行效率而言都是不利的。其实对其填充的最终目的是为了计算机高效寻址。
至此,我们已经了解了对象在堆内存中的整体结构布局,如下图所示: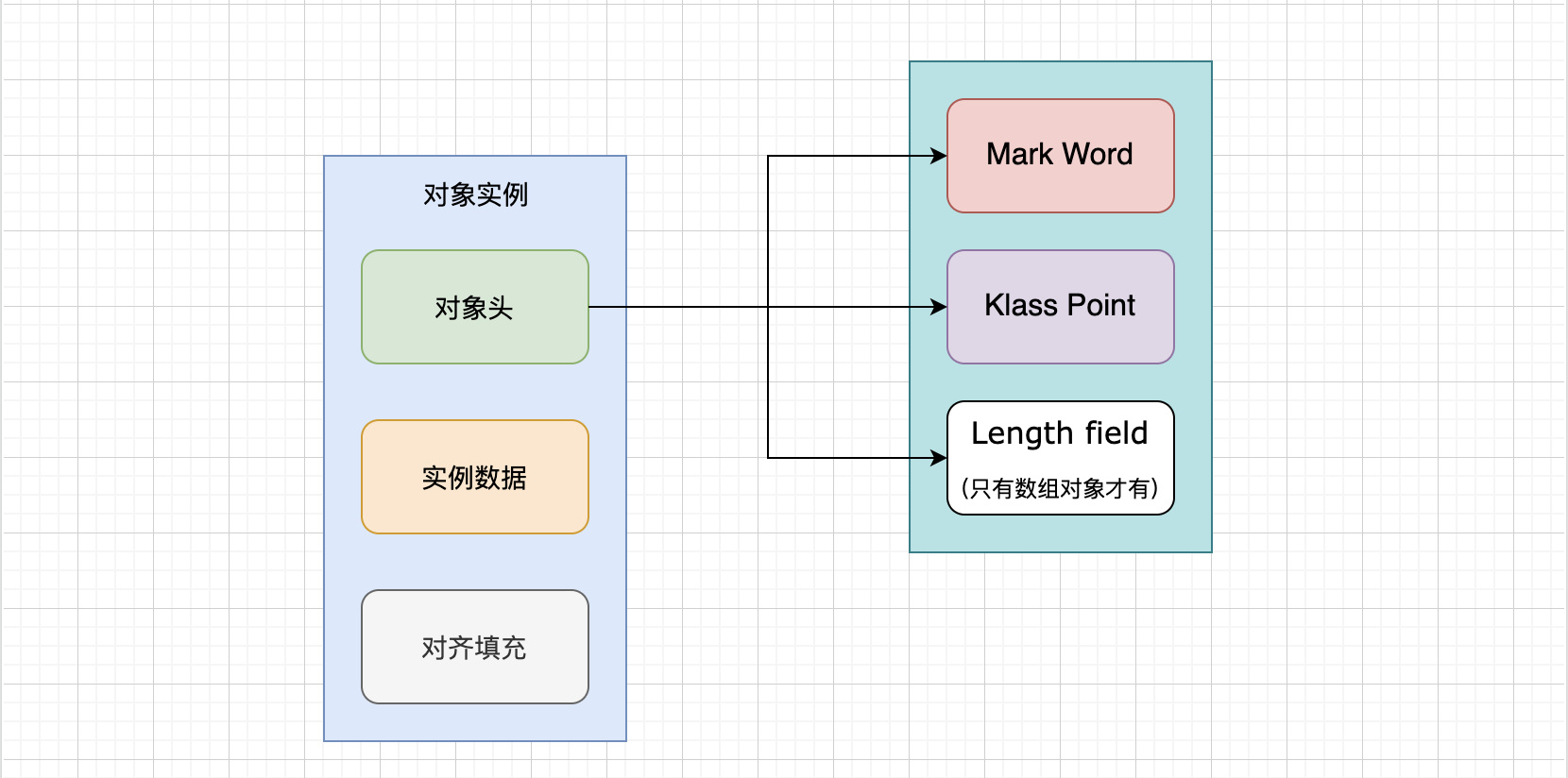
三、总结
一个Java对象由三部分组成,分别是对象头、实例数据、填充数据:
- 对象头占12个字节(64位JVM),包括
mark word、klass pointer两个部分 - 实例数据中包括基本类型和引用类型,基本类型占对应大小,引用类型占用1个字节
- 当对象的大小不是8字节的倍数的时候,对齐数据则会进行填充




