10万TPS级高并发系统——10万量级文本关键字匹配过滤
一、背景简介
消息发送管控平台中有个很重要的能力就是文本关键字检测,比如检测一段话中是否含有法轮功等敏感字段,这就涉及到关键字匹配算法。在该项目中每条消息都要经过关键词过滤,通过后才能下发。关键字匹配有两种形式,分为单一关键字和逻辑关键字。
1.1 单一关键字
单一关键字指单个单词,如:法轮功,炸金花,一条龙服务等涉恐、涉赌、涉黄等关键字,单个的关键字在系统数据库中的数量在9万+,消息下发时需要检测文本中是否包含数据库中单个关键字。
1.2 逻辑关键字
逻辑关键字由多个单一关键字组合&&、||、!逻辑运算符,即匹配到的关键字满足逻辑关键字中的逻辑运算逻辑才进行管控。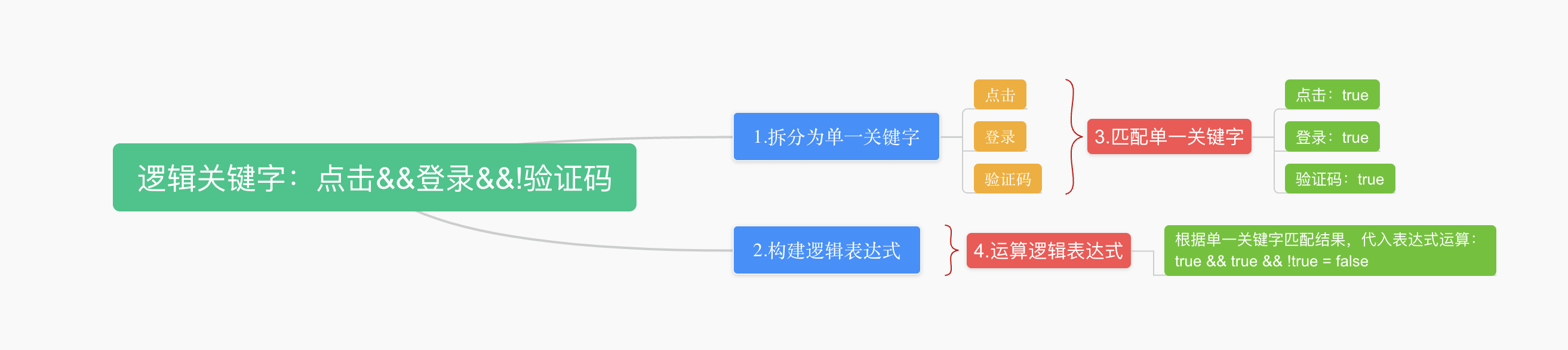
二、性能要求
消息发送管控平台关键字整体数据规模为10万量级,其中单一关键字数量为9万,逻辑关键字数量为1万。消息管控平台的安全审核接口整体的平均响应时间为50ms。
三、方案预研
我们先分析梳理常用的关键词匹配算法,再根据上述业务需求及平台性能要求,进行方案设计及落地实现。常用的关键词匹配算法有:暴力匹配算法、KMP算法、Boyer-Moore算法、双数组Trie、AC自动机、基于双数组Trie的AC自动机等。下面我们结合各个算法的优缺点、性能、及适用场景进行选择分析。
3.1 算法对比分析
各个算法原理相见:常见的关键字匹配算法
| 算法名称 | 适用场景 | 性能 |
|---|---|---|
| 暴力匹配算法(Brute Force) | 小规模数据或者模式串较短的简单匹配场景 | 在规模较小的情况下能够工作,但随着数据规模增大,性能迅速下降。 |
| KMP算法(Knuth-Morris-Pratt算法) | 需要处理长模式串或者大量数据的字符串匹配任务 | 对于大规模数据和长模式串有较好的性能表现,常用于实际应用中。 |
| Boyer-Moore算法 | 处理长模式串和大规模数据,尤其适用于多次匹配的情况 | 在实际应用中,通常能提供较好的性能表现,特别是在模式串相对较长时 |
| Trie树 | 需要快速存储和检索字符串集合的应用,如字典、自动完成、拼写检查等。 | 在处理字符串集合和前缀匹配任务时,能够提供稳定和高效的性能表现。 |
| 双数组Trie(Double-Array Trie,DAT) | 需要高效存储和查询大规模字符串集合的场景,特别是需要频繁进行前缀匹配或者完全匹配的应用。 | 在大规模数据和长字符串的存储和查询中,双数组Trie能够显著提升性能,特别是在内存使用和查询速度上。 |
| AC自动机(Aho-Corasick自动机 | 需要在大规模文本中同时匹配多个模式串的高效搜索应用场景,如关键字过滤、文本搜索引擎、网络安全等领域。 | 在处理多模式匹配问题时,AC自动机通常能够提供优秀的性能表现,特别是在模式串数量较多或文本规模较大时。 |
| 基于双数组Trie的AC自动机 | 需要在大规模文本中同时匹配多个模式串的高效搜索应用场景。 | 在处理多模式匹配问题时,基于双数组Trie的AC自动机通常能够提供优秀的性能表现,特别是在模式串较多或文本较大时。 |
根据管控平台关键字管控的业务要求,关键字匹配算法需要支持两大特点:大规模数据、多模式串匹配,才能在单一关键字和逻辑关键字匹配上有较好的性能表现,根据上述算法的特点及性能,基于双数组Trie的AC自动机算法符合我们的业务需求。
3.2 基于双数组Trie的AC自动机
四、方案设计
根据业务要求我们需要实现消息内容的单一关键字和逻辑关键字的匹配,下面为关键字匹配算法代码实现及使用示例。
4.1 单一关键字匹配
单一关键字匹配可以直接使用AhoCorasickDoubleArrayTrie实现,算法如下:
4.1.1 引入Maven依赖
<dependency>
<groupId>com.hankcs</groupId>
<artifactId>aho-corasick-double-array-trie</artifactId>
<version>1.2.3</version>
</dependency>4.1.2 封装AhoCorasickDoubleArrayTrie
/**
* AhoCorasickDoubleArrayTrie 算法包装类
*/
private class AhoCorasickEntry {
private Map<String, String> map = new ConcurrentHashMap<>();
private AhoCorasickDoubleArrayTrie<String> trie = new AhoCorasickDoubleArrayTrie<>();
public boolean addKeyword(String keyword) {
if (map.containsKey(keyword)) {
return false;
}
map.put(keyword, keyword);
return true;
}
public void build() {
trie.build(map);
}
public List<AhoCorasickDoubleArrayTrie.Hit<String>> parseText(String content) {
return trie.parseText(content);
}
}4.1.3 初始化及使用AhoCorasickDoubleArrayTrie
下面是一个基于AhoCorasickDoubleArrayTrie的初始化及使用案例:
public class KeywordHandler {
AhoCorasickEntry ahoCorasickEntry = new AhoCorasickEntry();
/**
* 初始化AhoCorasickDoubleArrayTrie
*/
public void initAhoCorasickEntry(List<String> keywordList) {
keywordList.forEach(keyword -> ahoCorasickEntry.addKeyword(keyword));
ahoCorasickEntry.build();
}
/**
* 获取消息内容中匹配到的关键字集合
*/
public Set<String> getMatchedKeywordSet(String msgContent) {
List<AhoCorasickDoubleArrayTrie.Hit<String>> wordList = ahoCorasickEntry.parseText(msgContent);
if (CollectionUtils.isEmpty(wordList)) {
return Collections.emptySet();
}
return wordList.stream()
.map(hit -> hit.value)
.collect(Collectors.toSet());
}
}4.2 逻辑关键字匹配
逻辑关键字的匹配包括两个步骤:第一步匹配逻辑关键字中每个单一关键字,第二部根据第一步匹配到结果再进行逻辑运算。关键字的逻辑运算我们使用开源的高性能表达式引擎AviatorScript。
4.2.1 AviatorScript简介
AviatorScript 是一门高性能、轻量级寄宿于 JVM (包括 Android 平台)之上的脚本语言。
4.2.2 引入AviatorScript依赖
<dependency>
<groupId>com.googlecode.aviator</groupId>
<artifactId>aviator</artifactId>
<version>{version}</version>
</dependency>4.2.3 逻辑关键字匹配实现
前面讲到逻辑关键字的匹配分为两个步骤,第一步先是根据逻辑运算符将逻辑关键字拆分为单一关键字,将所有的拆分后的逻辑关键字构建一个AhoCorasickDoubleArrayTrie进行关键字匹配。
public class ComplexKeyword {
/**
* 逻辑关键字
*/
private String expression;
/**
* 编译后的逻辑关键字
*/
private Expression compiledExpression;
private List<String> keywordList;
public ComplexKeyword(String expression) {
this.expression = expression.toLowerCase();
this.compiledExpression = AviatorEvaluator.compile(this.expression);
// 逻辑关键字表达式拆词
String[] keywords = this.expression.split("[| & ( ) !]");
keywordList = filterBlankAndSort(keywords);
}
public List<String> filterBlankAndSort(String[] keywords) {
Set<String> keywordSet = new HashSet<>(Arrays.asList(keywords));
keywordSet.remove("");
List<String> keyList = new ArrayList<>(keywordSet);
keyList.sort((keyword1, keyword2) -> keyword2.length() - keyword1.length());
return keyList;
}
/**
* 获取逻辑关键字运算参数Map
*/
private Map<String, Object> getEnvMap(Set<String> matchedKeywordSet) {
return keywordList.stream()
.collect(Collectors.toMap(
keyword -> keyword,
matchedKeywordSet::contains,
(left, right) -> right
));
}
private String getTargetExpression(Set<String> matchedKeywordSet) {
Map<String, String> env = keywordList.stream()
.collect(Collectors.toMap(
keyword -> keyword,
keyword -> String.valueOf(matchedKeywordSet.contains(keyword)),
(left, right) -> right
));
// 排序后的keywordList,目的是在替换时先替换长度较大的关键字,避免相同前缀的短关键字被先替换
for (String key : keywordList) {
expression = expression.replaceAll(key, env.get(key));
}
return expression;
}
/**
* 执行逻辑关键字表达式运算
*/
public boolean execute(Set<String> matchedKeywordSet) {
try {
// 优先使用预编译的表达式传入参数进行逻辑运算(性能高)
return compiledExpression.execute(getEnvMap(matchedKeywordSet)).equals(true);
} catch (Exception e) {
// 表达式执行失败,则根据关键字匹配结果获取匹配结果的表达式(性能低于预编译)
return AviatorEvaluator.execute(getTargetExpression(matchedKeywordSet)).equals(true);
}
}
public String getExpression() {
return expression;
}
}下面为遍历逻辑关键字列表,检测是否有匹配的逻辑关键字:
public Optional<String> matchComplexKeyword(List<ComplexKeyword> complexKeywords, Set<String> matchedKeywordSet) {
if (CollectionUtils.isEmpty(complexKeywords)) {
return Optional.empty();
}
complexKeywords.forEach(complexKeyword -> {
if (complexKeyword.execute(matchedKeywordSet)) {
return complexKeyword.getExpression();
}
});
return Optional.empty();
}4.3 性能验证
下面结合实际业务场景的数据量测试单一关键字和逻辑关键字匹配中两个核心处理步骤AhoCorasickDoubleArrayTrie和AviatorScript的性能表现。
4.3.1 AhoCorasickDoubleArrayTrie性能测试
选取10个消息模板进行测试,消息模板内容如下:
【xx商场】亲爱的会员,你好!國庆节马上到来,针对新老用户我们特推出5.5折优惠活动,只要到场凭会员卡可领取精美小礼物一件,数量有限先到先得!退订回T
【xx教育】高一升高二暑期补习班开课了,开设数学、物理、化学、英语等四科。开课时间7月15日。地点:xx.有意咨询或回复短信,汪老师:xx 退订回T
一个节日思念无数,一条短信祝福万千。端午节到了,祝你节日安康,同时祝你健健康康地,快安康乐地,和和美美地,顺顺利利地过好生命中的每一天。
xx大药房】积分当钱花,好礼送不停!xx药店年中大促暨积分兑换开始啦!丰富礼品等你来。24-31日进店销费送xx、xx、xx等。钙片仅1元!退订回T
【xx】您好,xx经理打扰您!邀约您参与xx举办的xx展会,相信通过此次展会您能够收获到更多的商业朋友,为自己的企业创造更多的新机遇! x月x日是参展日,望届时与会参观交流,期待您的光临!咨询电话:xx,退订回T
【xx游泳馆】绿道,全家的选择。带上家里的小朋友一起体验不一样的水世界!地址:xx,电话xx.退订回T
【xx银行】鉴于您信誉良好,诚邀您办理2万元信用卡,点击即可办理https://xx,退订回TD
【xx装饰】尊敬的xx先生您好!首先感谢您相信xx装饰!希望我们的设计师能给您带来关于装修想要设计方案,有其他咨询可随时联系xx。祝您生活愉快!
【xx管理局】紧急通知:因近日有大到暴雨,造成降雨量较大,现在应因地制宜排水晾田,尤其是低洼地块更应及时排水,防止倒灌发生,希望引起重视。
【xx市】尊敬的市民朋友们,2020年春节即将到来,让我们众志成城,严守禁放新规维护城市环境、为了美好生活!祝您节日快乐阖家幸福万事如意!测试代码如下:
public class AhoCorasickDoubleArrayTrieTest {
public static void main(String[] args) throws IOException {
KeywordHandler keywordHandler = getKeywordHandle();
List<String> contents = Files.readAllLines(Paths.get("content.txt"));
long startTime = System.currentTimeMillis();
contents.forEach(content -> matchKeyword(keywordHandler, content));
long times = System.currentTimeMillis() - startTime;
System.out.println("总耗时:" + times + ",平均耗时:" + times / contents.size() + "ms");
}
public static void matchKeyword(KeywordHandler keywordHandler, String content) {
long startTime = System.currentTimeMillis();
Set<String> matchedKeywordSet = keywordHandler.getMatchedKeywordSet(content);
System.out.println("单条文本关键字匹配耗时:" + (System.currentTimeMillis() - startTime) + "ms");
// matchedKeywordSet.forEach(System.out::println);
}
public static KeywordHandler getKeywordHandle() throws IOException {
KeywordHandler keywordHandler = new KeywordHandler();
// 文件路径:https://github.com/hankcs/AhoCorasickDoubleArrayTrie/blob/master/src/test/resources/cn/dictionary.txt
keywordHandler.initAhoCorasickEntry(getKeywordListForTest("dictionary.txt"));
return keywordHandler;
}
/**
* 读取本地字典文件作为关键字,文件有15万行
*/
public static List<String> getKeywordListForTest(String filePath) throws IOException {
Path path = Paths.get(filePath);
return Files.readAllLines(path);
}
}执行结果如下:
单条文本关键字匹配耗时:6ms
单条文本关键字匹配耗时:1ms
单条文本关键字匹配耗时:0ms
单条文本关键字匹配耗时:0ms
单条文本关键字匹配耗时:0ms
单条文本关键字匹配耗时:0ms
单条文本关键字匹配耗时:0ms
单条文本关键字匹配耗时:0ms
单条文本关键字匹配耗时:0ms
单条文本关键字匹配耗时:0ms
总耗时:8,平均耗时:0ms根据测试结果来看,在15万级的关键字匹配中,消息内容关键字匹配耗时仅在初次耗时较高,整体的平均耗时小于1ms, 该性能满足系统接口整体性能要求。
4.3.2 AviatorScript性能测试
public class AviatorScriptTest {
public static void main(String[] args) throws IOException {
List<ComplexKeyword> compiledKeywords = buildComplexKeyword(getComplexKeywords());
int count = 10;
long startTime = System.currentTimeMillis();
for (int i = 0; i < count; i++) {
Set<String> matchedKeywordSet = getMatchedKeywordSet();
matchComplexKeywords(compiledKeywords, matchedKeywordSet);
}
long times = System.currentTimeMillis() - startTime;
System.out.println("总耗时:" + times + "ms, 平均耗时:" + times / count + "ms");
}
public static void matchComplexKeywords(List<ComplexKeyword> compiledKeywords, Set<String> matchedKeywordSet) {
long startTime = System.currentTimeMillis();
compiledKeywords.forEach(complexKeyword -> complexKeyword.execute(matchedKeywordSet));
System.out.println("单条内容的逻辑关键字运算耗时:" + (System.currentTimeMillis() - startTime) + "ms");
}
public static List<ComplexKeyword> buildComplexKeyword(List<String> keywordExpression) {
return keywordExpression.stream()
.map(expression -> {
try {
return new ComplexKeyword(expression);
} catch (Exception e) {
return null;
}
})
.filter(Objects::nonNull)
.collect(Collectors.toList());
}
private static Set<String> getMatchedKeywordSet() {
Set<String> matchedKeywordSet = new HashSet<>();
Random rand = new Random();
matchedKeywordSet.add("关键字" + rand.nextInt(1000));
matchedKeywordSet.add("关键字" + rand.nextInt(1000));
matchedKeywordSet.add("关键字" + rand.nextInt(1000));
return matchedKeywordSet;
}
/**
* 根据字典文件生成1万个包含两个逻辑运算符的逻辑关键字
*
* @return 返回逻辑关键字表达式
*/
public static List<String> getComplexKeywords() throws IOException {
List<String> dictionary = Files.readAllLines(Paths.get("dictionary.txt"));
int complexKeywordSize = 10 * 1000;
int index = 10;
List<String> complexKeywords = new ArrayList<>(complexKeywordSize);
while (complexKeywords.size() < complexKeywordSize) {
String keyword1 = dictionary.get(index++);
String keyword2 = dictionary.get(index++);
String keyword3 = dictionary.get(index++);
String complexKeyword = keyword1 + getRandomOperator() + keyword2 + getRandomOperator() + keyword3;
complexKeywords.add(complexKeyword);
}
return complexKeywords;
}
/**
* 随机返回一个逻辑运算符
*/
public static String getRandomOperator() {
// 创建包含特定字符串元素的List
List<String> elements = new ArrayList<>();
elements.add("&&");
elements.add("||");
elements.add("&&!");
elements.add("||!");
// 使用Random类生成一个随机索引
Random random = new Random();
int randomIndex = random.nextInt(elements.size());
// 根据随机索引获取列表中的元素
return elements.get(randomIndex);
}
}执行结果如下:
单条内容的逻辑关键字运算耗时:69ms
单条内容的逻辑关键字运算耗时:10ms
单条内容的逻辑关键字运算耗时:8ms
单条内容的逻辑关键字运算耗时:8ms
单条内容的逻辑关键字运算耗时:9ms
单条内容的逻辑关键字运算耗时:7ms
单条内容的逻辑关键字运算耗时:8ms
单条内容的逻辑关键字运算耗时:7ms
单条内容的逻辑关键字运算耗时:7ms
单条内容的逻辑关键字运算耗时:7ms
总耗时:140ms, 平均耗时:14ms根据测试结果来看,1万量级的逻辑关键字运算中,仅在初次耗时较高,整体的平均耗时为14ms, 系统接口整体平均响应时长为50ms,可以满足性能要求。
五、总结
本文主要根据业务系统对关键字匹配的要求,设计方案实现单一关键字和逻辑关键字的匹配方案,技术方案及性能数据如下:
| 关键字类型 | 数据量级 | 技术方案 | 处理平均时长 |
|---|---|---|---|
| 单一关键字 | 15万+ | AhoCorasickDoubleArrayTrie多模式匹配 | <1ms |
| 逻辑关键字 | 1万 | 1.先用AhoCorasickDoubleArrayTrie匹配出关键字 2.再用AviatorScript进行逻辑运算 |
14ms |
以上为10万量级文本关键字匹配过滤方案,同时满足系统接口平均响应时长小于50ms的性能要求。





